6. 빅데이터 적재 개요
빅데이터 적재 및 하둡에 대한 간단한 개념을 알아보겠습니다.
추후에 더 자세한 HDFS의 아키텍처 및 맵리듀스 아키텍처를 알아보겠습니다.
1. 빅데이터 적재란?
데이터를 수집을 해왔으면 어딘가에 저장을 해야한다.
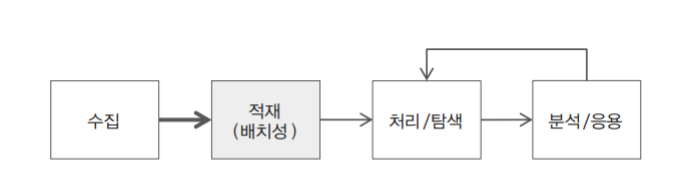
적재는 일반적으로 RDB나 파일을 생각을 할 수 있는데 빅데이터에서는 볼륨이 크고 형태도 다양하기 때문에 RDB나 파일 중간이라고 생각을 한다.
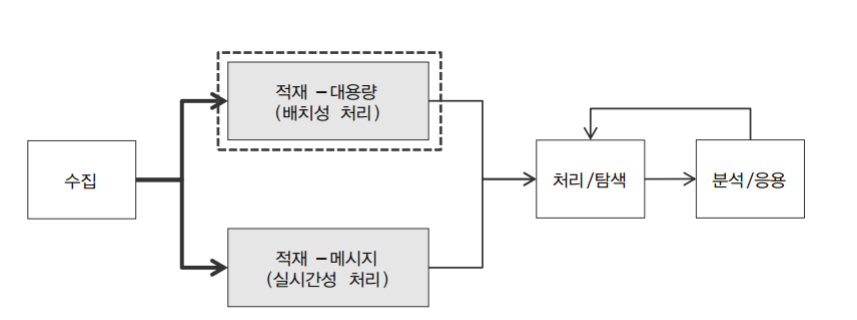
빅데이터 적재는 일반적으로 대용량데이터 적재와 실시간성 데이터 적재로 볼 수 있다.

원천데이터에는 정형,반정형,비정형 데이터가 있다. 문제는 형태도 다양한데 배치 수집도 다르다. 적재 저장소 유형은 크게 2가지로 구분된다. 배치처리와 실시간 처리로 구분된다. 배치처리는 큰 데이터를 처리, 실시간처리는 작은 메세지를 처리 한다고 볼 수 있다.
유형마다 사용되는 대표적인 기술은 아래와 같다.
- 대용량 데이터 처리 -> 하둡
- 대규모 메세지 저장 -> NoSQL
- 대규모 메세지 버퍼링 처리 -> 카프카
- 대규모 데이터 일부만 임시저장 -> redis(InMemoryDB)
2. 하둡 소개
하둡은 너무나도 잘 알려진 빅데이터의 핵심 소프트웨어다. 빅데이터의 에코시스템들은 대부분 하둡을 위해 존재하고 하둡에 의존해서 발전해가고 있다 해도 과언이 아니다. 하둡은 크게 두 가지 기능이 있다.
- 첫 번째가 대용량 데이터를 분산 저장하는 것이다.
- 분산 저장된 데이터를 가공/분석 처리하는 기능이다.
예를 들어 분산 저장은 1TB데이터를 블록단위(64MB or 128MB 등)로 3개의 노드에 저장한다고 생각하면 되고, 가공 처리는 노드마다 파일들이나눠서 저장되어있기때문에 분산된 데이터들을 활용하기 위해서는 별도로 처리를 해야한다.
3. 하둡 기본적인 구성요소
- DataNode
블록(64MB or 128MB 등) 단위로 분할된 대용량 파일들이 DataNode의 디스크에 저장 및 관리를 한다.
- NameNode
많은 n개의 DataNode에 저장된 파일들의 메타 정보를 메모리상에서 로드해서 관리를 해준다.
- EditsLog
파일들의 변경 이력(수정, 삭제 등) 정보가 저장되는 로그 파일
- FsImage
NameNode의 메모리상에 올라와있는 메타 정보를 스냅샵 이미지로 만들어 생성한 파일
4. 하둡 1.x 구성요소

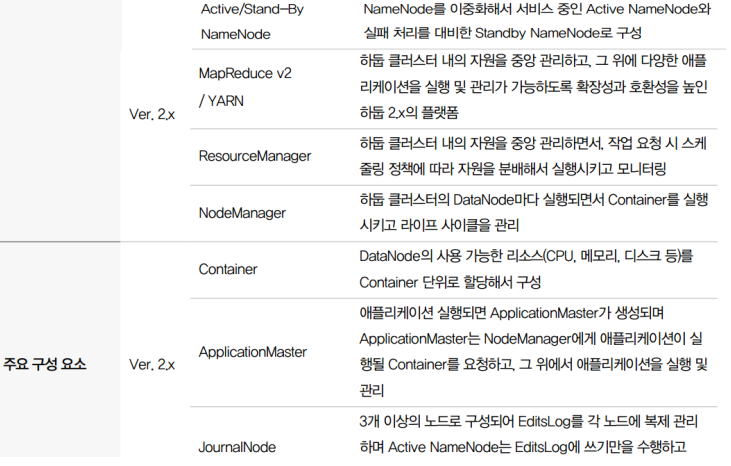
5. 하둡 2.x 구성요소
하둡 버전 2.x로 오면서 자체적으로 NameNode Active/Stand-By가 추가되었고, MapReduce에서 YARN이 추가되었다. 기존 하둡1.x 버전에서는 리소스 관리를 취약하다는 단점이 있어서 해결책으로 나왔다.
6. 하둡 1.x 아키텍처
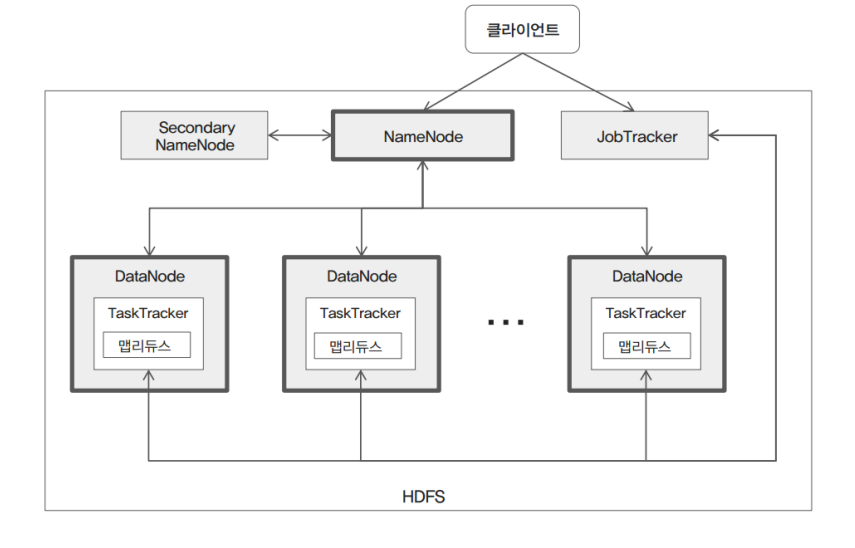
클라이언트가 데이터를 저장한다고 했을 때 DataNode에 데이터를 분산해서 저장을 한다. NameNode 파일 메타데이터 정보를 관리하며 클라이언트 요청을 처리한다. Secondary NameNode는 백업 관리하는 역할이다. JobTracker는 맵리듀스를 스케줄링을 담당하고 모니터링을 한다.
7. 하둡 2.x 아키텍처
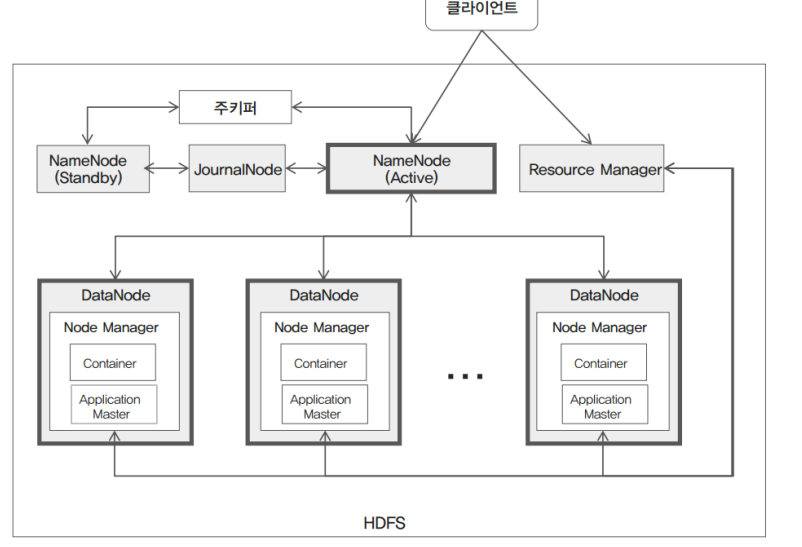
NameNode Active/Stand-By 및 JournalNode가 추가되었고 주키퍼 분산 코디네이터 역할을 한다. Resource Manager가 자원들을 관리를 해준다. 하둡1.x 보다 안정성이 좋다.
8. 하둡의 맵리듀스
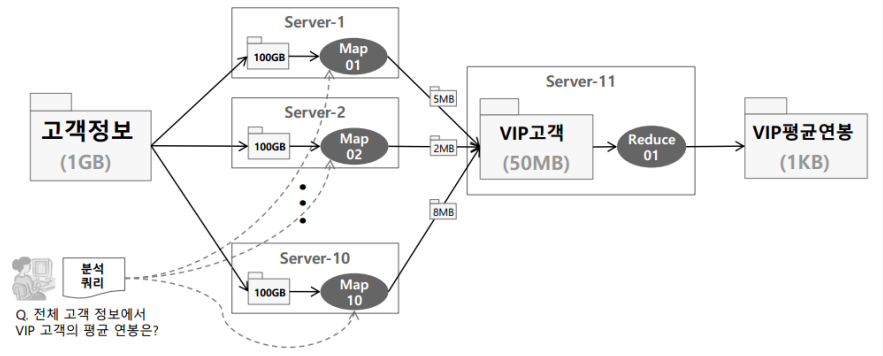
분산병렬 처리에서의핵심은 여러 컴퓨터에 분산 저장돼 있는 데이터로부터 어떻게 효율적으로 일을 나눠서(Map) 실행시킬 수 있는지, 다음으로 여러 컴퓨터가 나눠서 실행한 결과들을 어떻게 하나로 모으냐(Reduce)는 것이다. 이를 쉽고 편리하게 지원하는 프레임워크가 하둡의 맵리듀스(MapReduce)다.
9. 주키퍼 소개
분산 시스템을 설계 하다보면, 가장 문제점 중의 하나가 분산된 시스템간의 정보를 어떻게 공유할것이고, 클러스터에 있는 서버들의 상태를 체크할 필요가 있으며 또한, 분산된 서버들간에 동기화를 위한 락(lock)을 처리하는 것들이 문제로 부딪힌다. 이러한 문제를 해결하는 시스템을 코디네이션 서비스 시스템 (coordination service)라고 하는데, Apache Zookeeper가 대표적이다.

주키퍼는 하둡에서만 사용되는 것이 아니라 하둡에코환경시스템 SW에서도 범용적으로 사용이 된다.
9. 주키퍼 아키텍처
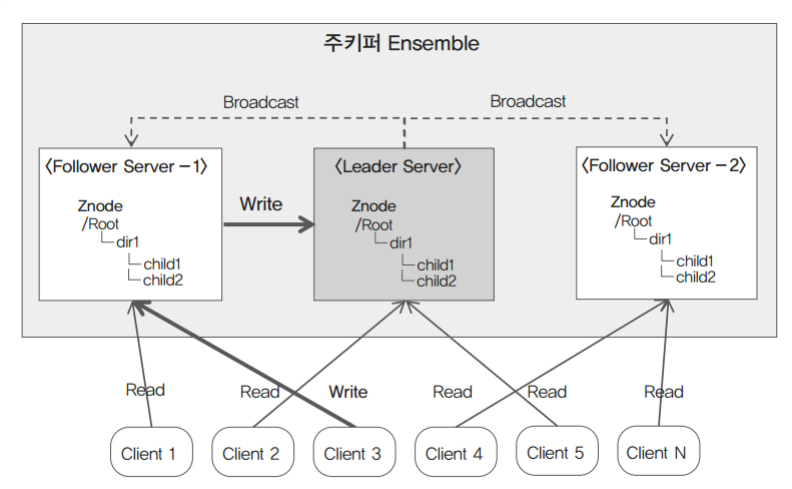
3대의 주키퍼 서버가 있는데 그 중 하나는 반드시 Leader Server 여야한다. 각각의 분산된 서버(client)들은 본인들의 환경설정보 및 데이터 정보를 주키퍼 Ensemble에 저장을 한다. 예를 들어 client3번이 Follower server-1에 변경된 사항을 저장을 하고 Follower server-1은 Leader Server에 변경된 서버에 알리고 Leader Server가 나머지 Follower server에 공유를 한다.
출처 : 실무로 배우는 빅데이터 기술 : 데이터 수집, 적재, 처리, 분석, 머신러닝까지[2판]