7. 빅데이터 실시간 적재 - HBase & Redis
1. 빅데이터 실시간 처리
빅데이터 출현으로 관계형 데이터베이스가 한계가 발생합니다. 이를 극복하기 위해 NoSQL 소프트웨어 중 하나인 HBase입니다. 관계형 데이터베이스는 ACID 원칙이 있습니다. ACID는 데이터의 유효성을 보장하기 위한, 트랜잭션의 특징들의 앞글자를 딴 단어입니다.
- Atomicity(원자성)
모든 작업이 반영되거나 모두 롤백되는 특성입니다.
- Consistency(일관성)
데이터는 미리 정의된 규칙에서만 수정이 가능한 특성을 의미합니다. 숫자컬럼에 문자열값을 저장이 안되도록 보장해줍니다.
- Isolation(고립성)
A와 B 두개의 트랜젝션이 실행되고 있을 때, A의 작업들이 B에게 보여지는 정도를 의미합니다.
- Durability(영구성)
한번 반영(커밋)된 트랜젝션의 내용은 영원히 적용되는 특성을 의미합니다.
수 없이 많은 트랜잭션이 발생하는 빅데이터에서는 RDBMS에 저장할 때 AICD를 지키기에는 무리가 있습니다. 그래서
ACID를 제공하지않는 NoSQL을 사용하게 시작했습니다. NoSQL는 key/value 구조이며, 고성능으로 쓰기와 읽기가 가능합니다.
HBase는 하둡기반 분산 컬럼 지향 기반의 NoSQL이며, HDFS의 데이터에 대한 실시간 임의 읽기/쓰기 기능을 제공합니다. 사용자는 HBase나 HDFS에 직접 데이터를 저장할 수 있고, 사용자는 데이터를 읽고 접근하는 것은 HBase를 통한 임의접근을 이용한다.
2. HBase 특징
예를 들어 1~10번 컬럼 데이터가 있다고 가정할 때 기존 관계형데이터베이스는 10번 데이터를 추출하고싶으면 1~9번 데이터까지 액세스하지만 HTable은 10번 컬럼데이터만 추출하기때문에 속도가 빠르다.

3. HBase 아키텍처
HBase는 HDFS위에 설치가 되고, HDFS의 확장성과 가용성을 물려받았습니다.
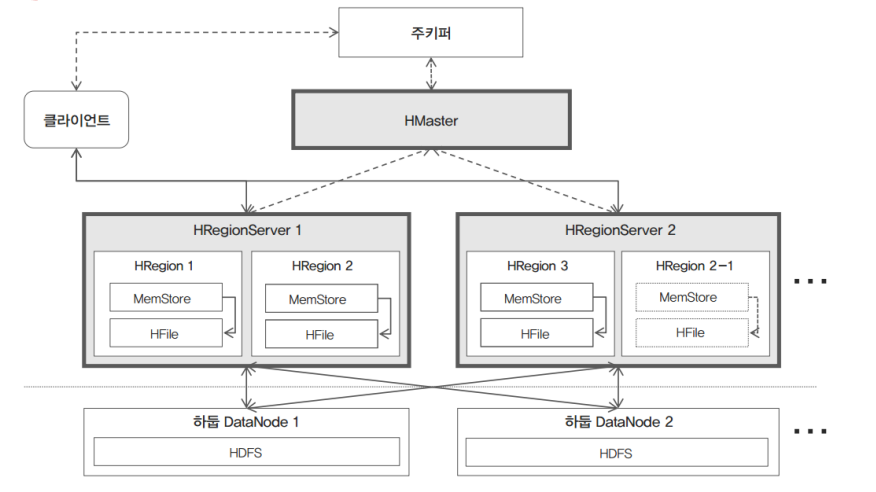
- 데이터 저장할 때
클라이언트는 HBase 테이블에 데이터를 저장을 하고 싶으면 주키퍼를 통해서 HBase 기본 정보와 해당 HRegion 정보를 알아내서 클라이언트가 HRegionServer에 접근을 해서 HRegion에 Memstore에 데이터를 저장을 하고 MemStore의 특정 크기 와 시점이 되면 HFile에 데이터를 내리고 HFile은 하둡에 영구저장합니다.
- 데이터 읽어올 때
클라이언트가 주키퍼를 통해 데이터 로우키를 알아낸다. 방법은 HMaseter에는 해당 HTable 메타 정보를 저장하고 있습니다. 메타 정보를 이용하여 해당 HRegion에 접근을 합니다. 만약 MemStore에 데이터가 있다면 MemStore에 있는 데이터를 전달을 해준다. 만약 MemStore에 데이터가 flush가 되었다면 HFile에서 찾게됩니다. 모든 데이터 스트림은 열려있고, HDFS에서 데이터를 빠르게 조회할 수 있다.
4. redis 특징
REDIS(REmote Dictionary Server)는 메모리 기반의 “키-값” 구조 데이터 관리 시스템이며, 모든 데이터를 메모리에 저장하고 조회하기에 빠른 Read, Write 속도를 보장하는 비 관계형 데이터베이스이다.
HBase와 redis의 차이점은 대규모 발생하는 실시간 데이터 중에서 HBase에 저장하기 전에 일부 특정 데이터들만 redis에 저장할 필요가 있을 때 사용한다는 점이다.

5. redis 아키텍처
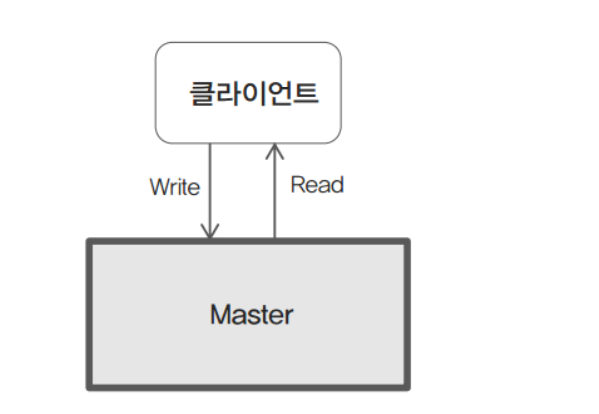
클라이언트에서 공유하고 싶은 데이터를 Master에 있는 메모리에 Write/Read를 하는 구조입니다.
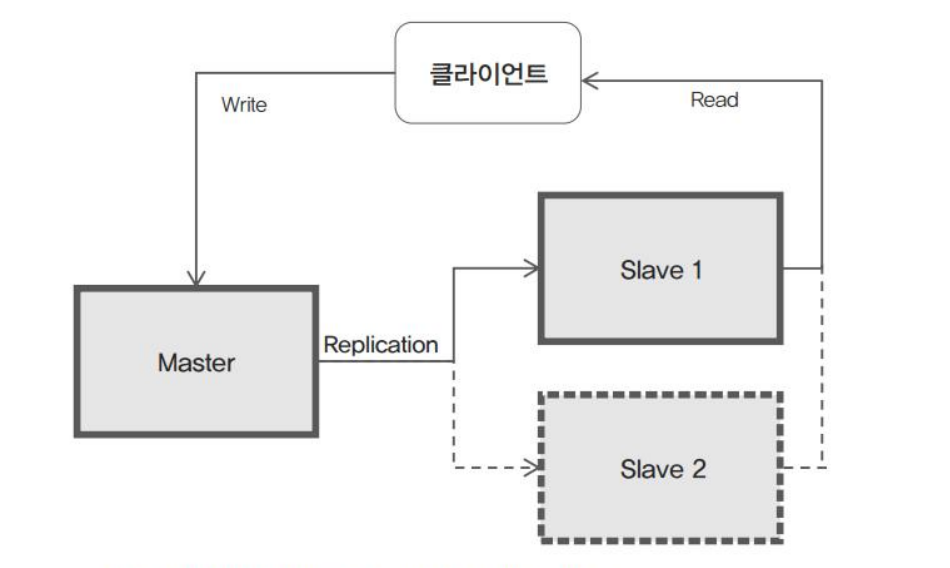
Master 구조와 Slave구조를 멀티 분산 구조로 만들었다. 클라이언트가 Cache에 기록할 때는 Master에 write를 하고 Master는 Slave에 복제하는 구조이다. 클라이언트는 데이터를 읽을 때는 Slave를 통해 읽는다.
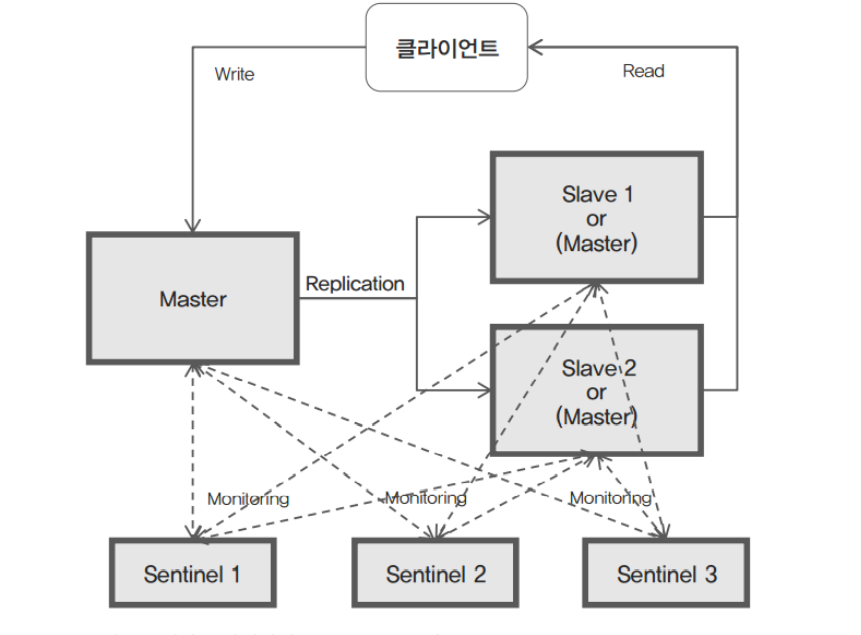
Single Master구조의 단점을 보완한 구조이며, Sentinel가 추가되었고, Master가 장애가 발생하지않도록 모니터링을 하고 있다가 Master가 장애가 발생한다면 Slave 중에 Master로 선출할 수 있는 기능을 가지고 있다. redis 3.x 부터 가능하다 안전성과 고가용성을 크게 높혀준 아키텍처이다.
출처 : 실무로 배우는 빅데이터 기술 : 데이터 수집, 적재, 처리, 분석, 머신러닝까지[2판]