고정 헤더 영역
상세 컨텐츠
본문
728x90
Yolo v5 모델을 학습을 시켜 마스크 쓴 사람 안 쓴 사람을 검출을 해보겠습니다.
학습은 google colab에서 진행을 했고, 데이터셋은 roboflow에서 마스크 데이터셋을 이용했습니다.
1. 마스크 데이터셋 다운로드
https://public.roboflow.com/object-detection/mask-wearing 로 접속을 한다. 로그인을 한 후 진행을 한다.
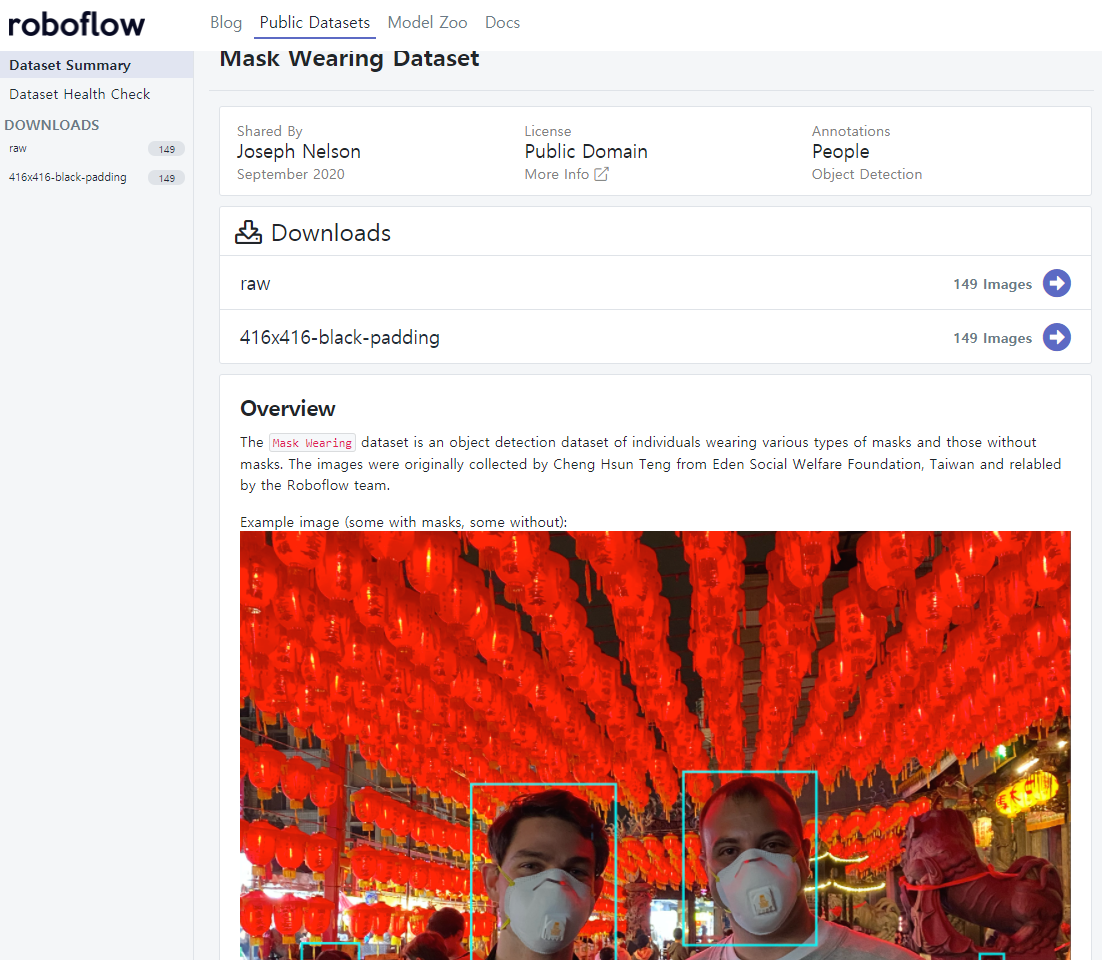
416x416-black-padding을 선택을 한다. 416 X 416 해상도 데이터 세트의 경우, 원본 이미지의 해상도가 다르다고 하더라도 패딩(padding)을 채워 넣어 416 X 416 해상도를 맞춘 것을 의미한다. 149개의 이미지로 구성이 되어있고 가볍게 테스트하기 좋다. 오른쪽 상단의 Download버튼을 클릭 후 Format을 YOLO v5 Pytorch를 선택을 한다.
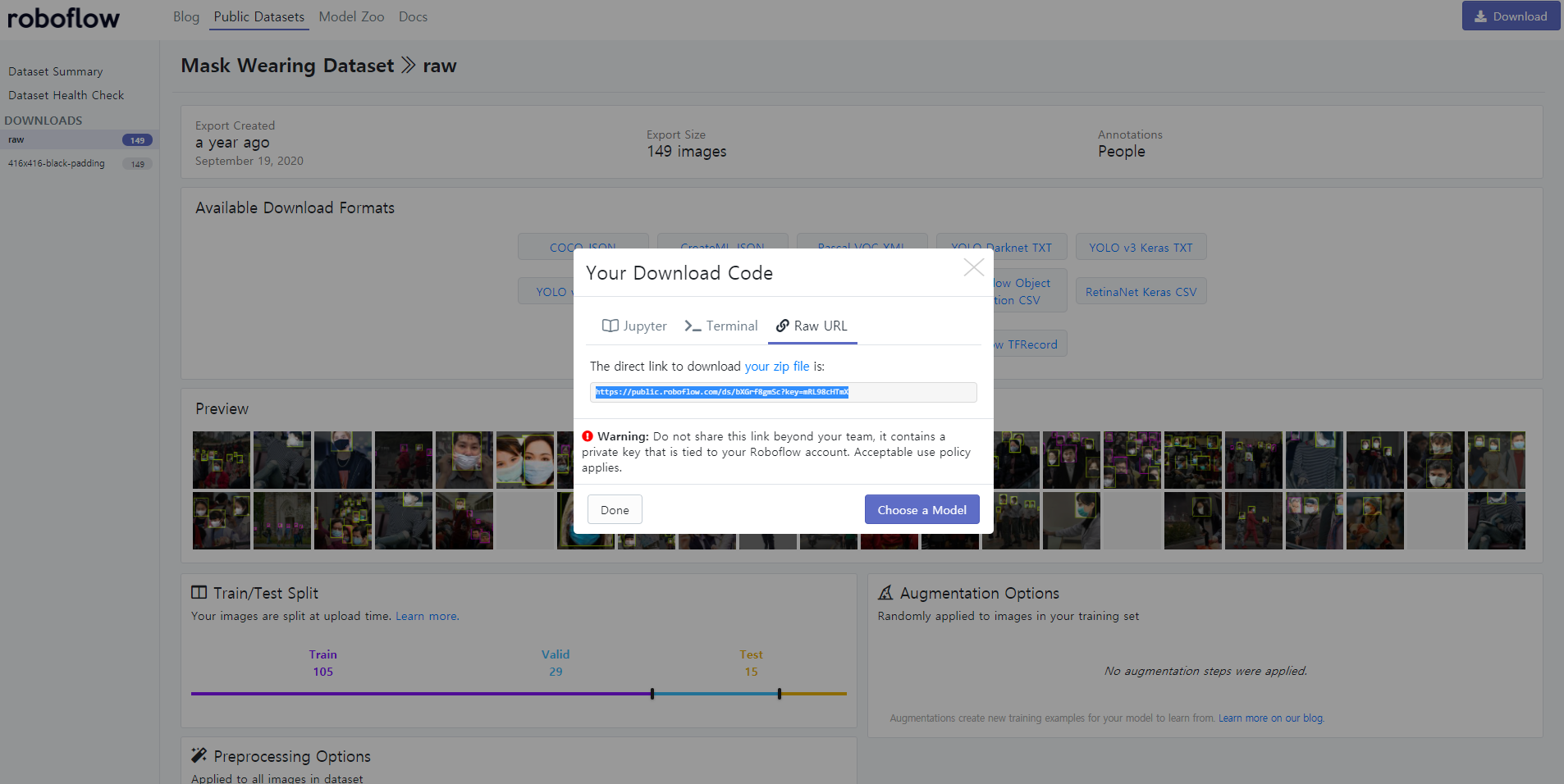
zip 파일로 다운로드할 수 도 있고 링크를 통해 다운로드할 수 있다. colab에서 테스트를 진행할 거여서 링크를 복사한다.
2. google colab 접속
https://colab.research.google.com/ 접속을 한 후 로그인을 해서 새 파일을 만든다.

상단의 런타임 -> 런타임 유형변경 -> GPU 선택 후 저장.
3. colab에서 데이터셋 다운로드
!curl -L (roblflow 링크) > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
다운로드를 진행을 하면 content폴더에 train, vaild, test, data.yaml 파일이 저장이 된다.
4. git clone으로 repository 다운
git clone으로 https://github.com/ultralytics/yolov5 에서 repository를 다운로드한다.
%cd /content/
!git clone https://github.com/ultralytics/yolov5
다운로드 후 yolov5 폴더가 생겼다.

5. requirements.txt 이용하여 라이브러리 설치
requirements.txt 파일안에 명시된 라이브러리를 설치를 한다.
!pip install -r yolov5/requirements.txt
다운로드가 진행이 된다.
6. 데이터셋 설정
%cat data.yaml
data.yaml 파일을 보게되면 traim 데이터셋과 val 데이터셋 경로 정보가 있고, mask, no-mask 2개의 클래스가 있는 것을 확인할 수 있다.
#클래스 개수를 num_classes에 대입
import yaml
with open("data.yaml", 'r') as stream:
num_classes = str(yaml.safe_load(stream)['nc'])
YOLOv5는 x(x-large), l(large), m(medium), s(small)의 4종류로 구성되는데 그중에서 s(small)를 사용해보고 yaml 파일 정보를 확인한다.
%cat /content/yolov5/models/yolov5s.yaml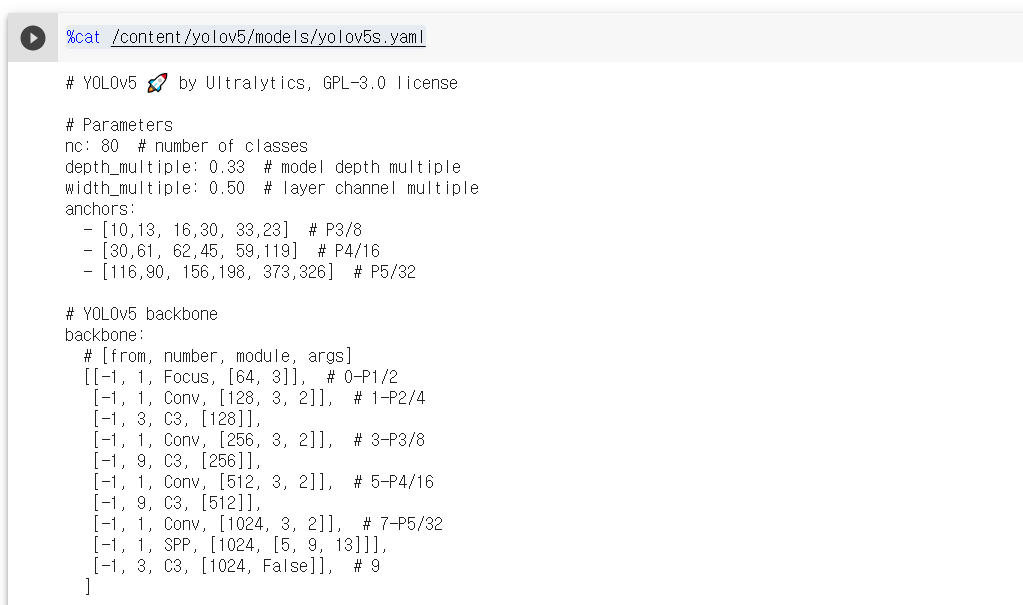
nc가 80으로 되어있다. 2개로 변경을 해야하는 작업을 한다.
from IPython.core.magic import register_line_cell_magic
@register_line_cell_magic
def writetemplate(line, cell):
with open(line, 'w') as f:
f.write(cell.format(**globals()))%%writetemplate /content/yolov5/models/custom_yolov5s.yaml
# parameters
nc: {num_classes} # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
7. Yolov5 모델 학습시키기
arguments값 속성이다.
- img: define input image size
- batch: determine batch size
- epochs: define the number of training epochs.
- data: set the path to our yaml file
- cfg: specify our model configuration
- weights: specify a custom path to weights
- name: result names
- nosave: only save the final checkpoint
- cache: cache images for faster training
%%time
%cd /content/yolov5/
!python train.py --img 416 --batch 16 --epochs 100 --data '../data.yaml' --cfg ./models/custom_yolov5s.yaml --weights '' --name yolov5s_results --cache
학습하면서 box_loss, obj_loss, cls_loss, reall, mAP 값을 확인할 수 있다.
Yolov5-> run -> train에서 학습하는 과정을 확인할 수 있다.
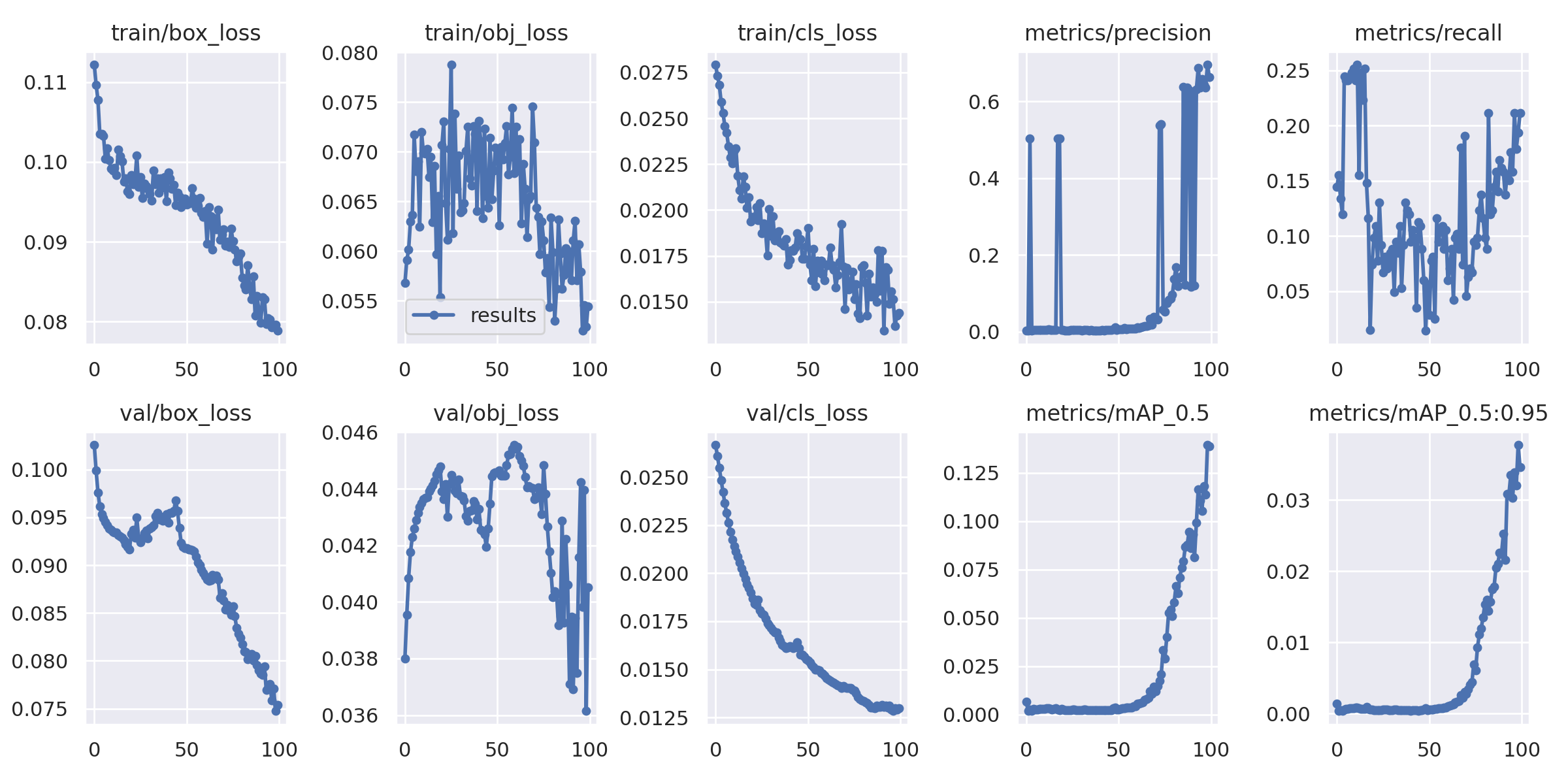


8. 학습된 Yolov5 모델을 이용하여 test 이미지 평가
test 폴더에 있는 이미지를 이용하여 평가를 한다.
학습이 끝나면 runs/train/yolov5s_results2/weights 폴더에 pt파일이 생성이 된다.
!python detect.py --weights runs/train/yolov5s_results2/weights/best.pt --img 416 --conf 0.4 --source ../test/images
import glob
from IPython.display import Image, display
for imageName in glob.glob('/content/yolov5/runs/detect/exp2/*.jpg'):
display(Image(filename=imageName))
print("\n")

테스트 이미지를 확인할 수 있다.


결과를 확인하니 정확하게 마스크를 검출하진 못하는거 같다. 데이터 수 증강, 모델 변경, 파라미터 값을 변경해보면서 다 향한 실험을 해봐야 할 것 같다.
9. 동영상으로 테스트 해보기
content폴더에 동영상 파일 업로드 후 테스트 진행
ex) --source ../test.mp4 --> 변경
!python detect.py --weights runs/train/yolov5s_results2/weights/best.pt --img 416 --conf 0.4 --source ../test.mp4

생각보다 정확도 높지 않은 것 같습니다.
출처 : https://colab.research.google.com/drive/1gDZ2xcTOgR39tGGs-EZ6i3RTs16wmzZQ#scrollTo=VUOiNLtMP5aG
https://github.com/ultralytics/yolov5
https://www.youtube.com/watch?v=fOskhV3t-k8
https://blog.roboflow.com/how-to-train-yolov5-on-a-custom-dataset/
728x90
'영상처리 및 분석' 카테고리의 다른 글
| 1. 영상처리 및 분석이란? (0) | 2022.08.03 |
|---|---|
| Face Detection MTCNN Pytorch로 학습하기 (0) | 2021.10.03 |





댓글 영역