고정 헤더 영역
상세 컨텐츠
본문
728x90
데이터 분석에서 자주 사용되는 앙상블 모델 및 분석에 대해 알아보겠습니다.
주어진 데이터를 이용해 여러개의 서로 예측모형을 생성한 후 예측 모형의 예측결과를 종합하여 하나의 최종 예측결과를 도출해내는 방법이다. 목표변수의 형태에 따라 분류분석, 회귀분석에 사용할 수 있지만 분류분석에 많이 쓰인다. 분류일 때는 가장 많이 선택된 클래스를 반환하고 회귀는 평균을 구해서 반환한다. 앙상블 기법은 가능하면 예측기가 서로 독립적으로 사용할 때 최고의 성능을 발휘한다. 예를 들어 의사결정나무, SVM분류기, 로지스틱 회귀 등 각 분류기에서 나온 클래스 중 가장많이 예측된 클래스를 반환해준다.

4개의 분류기중 3개가 1번 클래스를 예측하고 있다. 다수결로 결정하고 결과를 반환한다. 다수결 투표기는 개별 분류기 중 가장 뛰어난 것보다도 정확도가 높은 경우가 많다. 간접 투표기는 개별 분류기의 예측을 평균내어 가장 높은 확률의 클래스를 나타낼 수 있다.
1. 앙상블 기법 모형에 따른 3가지 기법
- 배깅(Bagging)
- 랜덤 포레스트(Random forest)
- 부스팅(Boostion)
2.배깅(Bagging)
- Bagging은 Bootstrap Aggregation의 약자이다.
- 배깅은 샘플을 여러 번 뽑아(Bootstrap) 각 모델을 학습시켜 결과물을 집계(Aggregration)하는 방법이다.
- 단일 seed 하나의 값을 기준으로 데이터를 추출하여 모델을 생성해 나는 것보다, 여러 개의 다양한 표본을 사용함으로써 모델을 만드는 것이 모집단을 잘 대표할 수 있게 된다.
- 훈련 세트에서 중복을 허용해서 샘플링하는 방법을 배깅이라 한다.
- 훈련 세트에서 중복을 허용하지 않고 샘플링하는 방법을 페이스팅이라고 한다.

배깅을 사용하다보면 같은 데이터가 여러번 나올 수 도 있고, 한번도 안 나올수도 있다. 한번도 안 나온 데이터로 테스트 데이터로 사용할 수 있다. 데이터를 샘플링할 수 있지만 특성 또한 샘플링할 수 있다.
- 훈련,특성 샘플 모두를 샘플링하는 것을 랜덤 패치(random patch) 방식이라고 한다.
- 훈련샘플을 모두 사용하고, 특성을 샘플링하는 것을 랜덤 서브 스페이스(random subspace)이라고 한다.
3. 랜덤 포레스트(Random forest)
랜덤포레스트는 배깅방법을 의사결정트리에 활용한 앙상블 방법이다. 나무가 모이면 숲이 되듯이 의사결정나무가 여러개 모이면 랜덤포레스트가 된다. 의사결정나무의 단점은 오버피팅이 발생할 확률이 높다는 것이다. 가지치기를 통해 오버피팅의 확률을 낮출 순 있지만 완벽히는 못막는다. 여러 의사결정나무를 앙상블하여 랜덤포레스트를 만들면 오버피팅 되는 단점을 해결할 수 있다.
- 원리
예를 들어 데이터 셋에 독립변수(특징, feature)가 30개라 있다. 30개의 특징을 하나의 의사결정나무 가지고 만들면 가지가 많아질 것이고, 오버피팅의 결과를 야기할 것입니다. 하지만 30개의 Feature 중 랜덤으로 5개의 Feature만 선택해서 하나의 결정 트리를 만들고, 또 30개 중 랜덤으로 5개의 Feature를 선택해서 또 다른 결정 트리를 만들고 이렇게 계속 반복하여 여러 개의 결정 트리를 만들 수 있다. 결정 트리 하나마다 예측 값을 반환하고 여러 결정 트리들이 내린 예측 값들 중 가장 많이 나온 값을 최종 예측값으로 정한다. 다수결의 원칙에 따르는 것이다.

4. 부스팅(Boosting)
부스팅은 가중치를 활용하여 약 분류기를 강 분류기로 만드는 방법이다. 부스팅은 틀린 문제를 노트에 적고 이것들에 집중을 하는 목적의 오답노트와 비슷한 개념으로 생각하면 되는데 즉, 틀린 케이스에 가중치를 줌으로써 이를 해결하는 것에 초점을 맞추는 모델이다. 처음 모델이 예측을 하면 그 예측 결과에 따라 데이터에 가중치가 부여되고, 부여된 가중치가 다음 모델에 영향을 준다. 잘못 분류된 데이터에 집중하여 새로운 분류 규칙을 만드는 단계를 반복한다.

- D1에서는 2/5 지점을 횡단하는 구분선으로 데이터를 나누어주었습니다. 하지만 위쪽의 +는 잘못 분류가 되었고, 아래쪽의 두 -도 잘못 분류되었다. 잘못 분류가 된 데이터는 가중치를 높여주고, 잘 분류된 데이터는 가중치를 낮추어 준다.
- D2를 보면 D1에서 잘 분류된 데이터는 크기가 작아졌고(가중치가 낮아졌고) 잘못 분류된 데이터는 크기가 커졌다.(가중치가 커졌다.) 분류가 잘못된 데이터에 가중치를 부여해주는 이유는 다음 모델에서 더 집중해 분류하기 위함이다. D2에서는 오른쪽 세 개의 -가 잘못 분류되었다.
- 따라서 D3에서는 세 개의 -의 가중치가 커졌다. 맨 처음 모델에서 가중치를 부여한 +와 -는 D2에서는 잘 분류가 되었기 때문에 D3에서는 가중치가 다시 작아졌다.
5. 배깅과 부스팅 차이
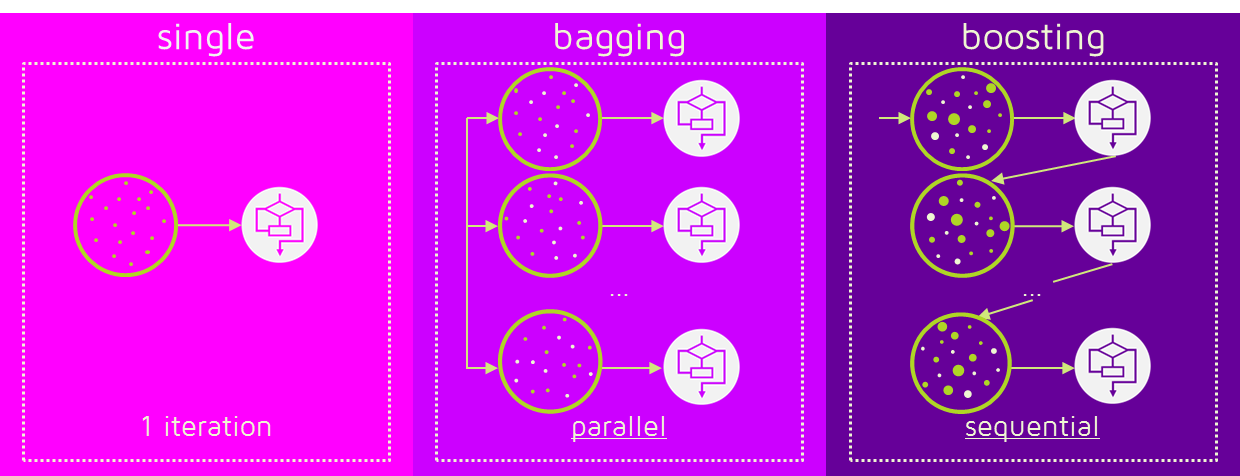
- 배깅은 병렬로 학습하는 반면, 부스팅은 순차적으로 학습을 하고, 한번 학습이 끝나면 가중치를 부여한다. 그렇게 부여된 가중치가 다음 모델의 결과 예측에 영향을 준다.
- 부스팅은 오답에 대해서는 높은 가중치를 부여하고, 정답에 대해서는 낮은 가중치를 부여한다. 따라서 오답을 정답으로 맞추기 위해 오답에 더 집중할 수 있다.
- 부스팅은 배깅에 비해 error가 적다. 즉, 성능이 좋다. 하지만 속도가 느리고 오버 피팅이 될 가능성이 있다.
- 배깅 과 부스팅 중 어떤걸 선택할 때 상황에 맞게 선택한다. 성능이 낮다면 부스팅, 오버피팅이 문제면 배깅이 적합하다.
728x90
'MachineLearning' 카테고리의 다른 글
| 분류 분석(Classification) (0) | 2021.09.17 |
|---|





댓글 영역