고정 헤더 영역
상세 컨텐츠
본문
728x90
code : https://github.com/kyeonminsu/R-Study/tree/main/1.%EA%B8%B0%EB%B3%B8%20%EB%AC%B8%EB%B2%95
1. 자료구조
자료형(Data Type)은 저장된 데이터의 성격(숫자형, 문자형, 논리형)을 의미한다. 이에 비해 자료구조(Data Structure)는 변수에 저장된 데이터의 메모리 구조(배열, 리스트, 테이블)를 의미한다. 이런 메모리 구조는 객체가 생성될 때 만들어지기 때문에 자료구조를 객체형(Object Type)이라 한다.
데이터타입은 앞에서 배웠듯이 mode()함수를 이용하여 데이터의 자료형을 확인할 수 있으며, class()함수를 이용하여 자료구조, 즉 메모리 구조를 확인할 수 있다.
R의 주요 자료구조
- Vector : 1차원 배열
- Matrix : 2차원 배열
- Array : 다차원 배열
- List : 중첩 자료구조
- Data Frame : 2차원 테이블 구조

vector의 특징
- vector는 1차원의 선형 자료구조 형태로 만들어진다.
- vector는 하나의 Data Type으로 구성된다. (vector의 구성요소는 모두 같은 Data Type이다.)
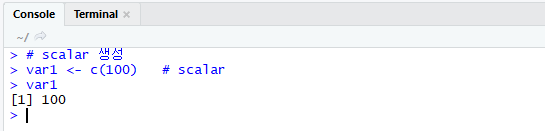
- vector 중에서 구성인자가 1개인 것을 scalar라고 한다. 따라서 scalar는 vector 이다.
scalar 생성의 예이다.
vector 생성방법 c() 함수
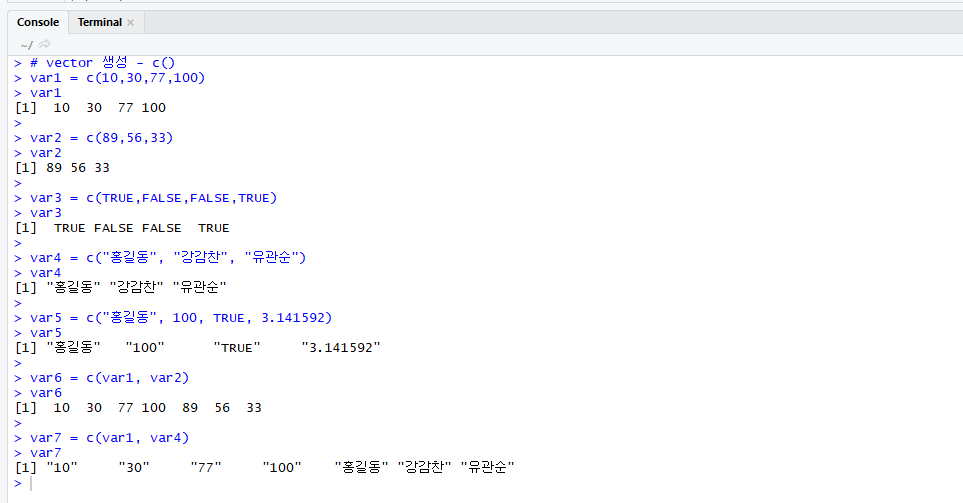
- c() 함수는 combine의 약자로 vector를 생성하는 가장 대표적인 방법이다. 일반적으로 규칙이 없는 데이터로 이루어진 vector를 생성할 때 이용된다. c() 함수는 vector들을 하나로 합쳐서 새로운 vector를 생성할 수도 있다.
- c() 함수는 vector를 생성할 때 사용되지만 다른 데이터 형태에서 일부의 데이터를 추출할 때도 사용된다.
c()함수 사용 예이다.
vector 생성방법 seq() 함수 (등차 수열)
- seq() 함수는 sequence의 약자로 콜론(:)의 일반형이라고 보시면 된다. 3개의 argument인 시작(from), 끝(to), 증감치(by)를 명시해서 규칙이 있는 수치형 vector를 생성할 수 있다.
- 인자의 위치에 따라 argument의 이름을 생략할 수 도 있지만 가능하면 argument 이름을 사용하는것이 가독성 측면에서 좋다.
seq()함수 사용 예이다.

vector 생성방법 seq() 함수 (등차 수열)
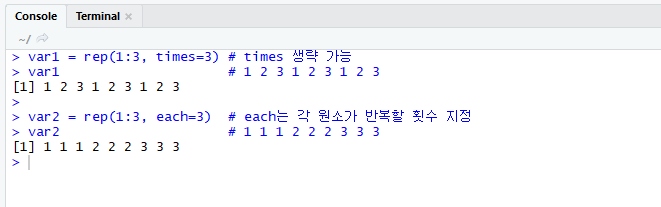
rep()함수는 지정하는 반복 횟수만큼 동일한 값이 복제되어 vector가 생성된다.
rep()함수 사용예이다.
vector에서 데이터 추출
- 수치형 vector에 수치형 scalar를 이용하여 사칙연산을 할 수 있습니다. 또한 vector와 vector간의 빠른 연산도 지원한다.
- vector의 길이가 동등할 경우 각 vector의 요소들끼리 연산을 수행한다.
- vector의 길이가 동등하지 않을 경우 연산과정에서 데이터의 개수가 적은 vector가 데이터의 개수가 많은 vector와 동일하게 데이터의 개수를 맞추게 된다. 즉, 데이터 개수가 차이나는 만큼 데이터의 개수가 늘어나게 된다. 새롭게 생성되는 데이터는 원래 가지고 있던 데이터를 순서대로 새롭게 생성되는 데이터에 지정하게 되는데 이러한 규칙을 재사용 규칙(recycling rule) 이라고 한다.

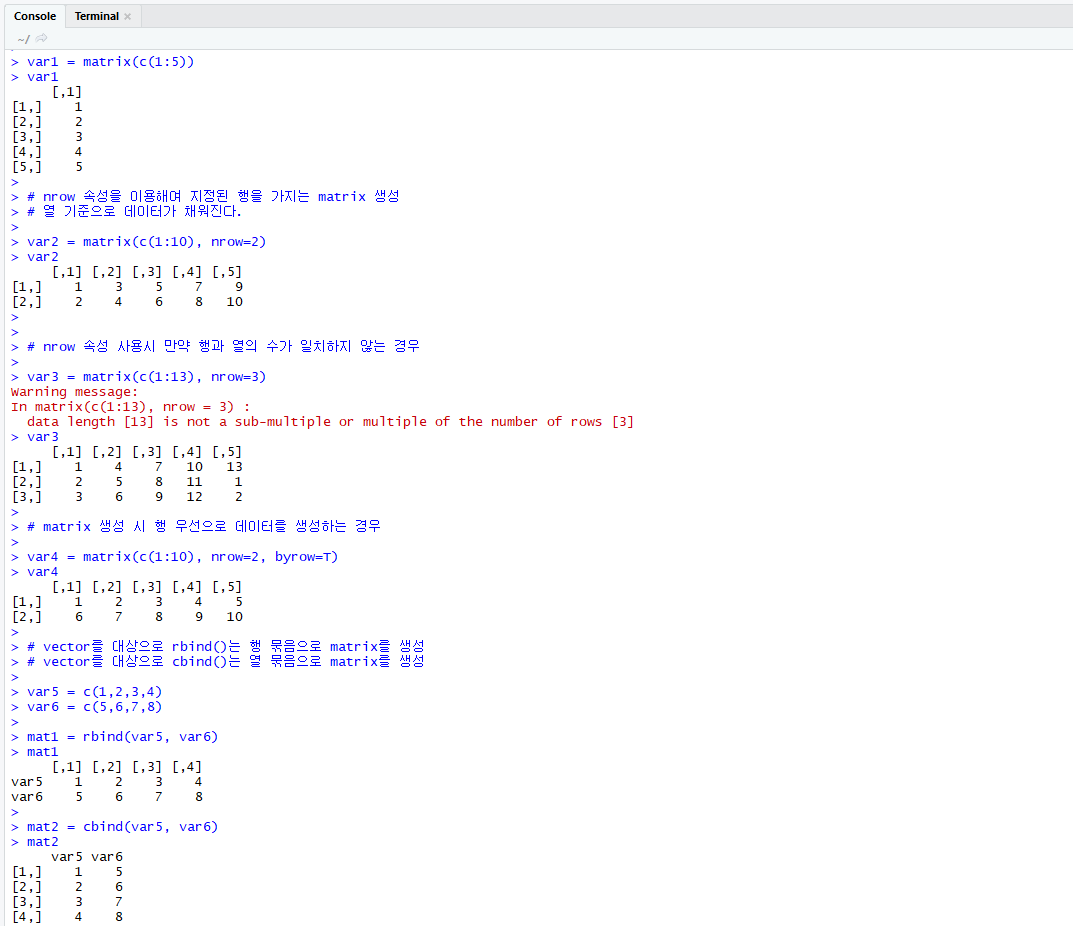
matrix(행렬) 특징
- Matrix 자료구조는 동일한 자료형을 갖는 2차원의 배열 구조를 의미한다.
- c() 함수를 이용하여 matrix를 생성할 수 있다. c()함수는 기본적으로 열을 기준으로 matrix를 생성한다.
matrix 연산
- matrix의 element단위의 곱 연산을 수행할 수 있다.
- matrix의 전치행렬을 쉽게 구할 수 있다.
- matrix product(행렬곱)을 쉽게 구할 수 있다.
- matrix inversion(역행렬)을 쉽게 구할 수 있다.

factor 특징
- R에서는 factor는 범주형 데이터를 표현하기 위한 데이터 형태이다. 범주형 자료로 표현되면 집단별로 통계분석과 같은 작업을 수행할 수 있다.
- 범주형 데이터란 데이터가 사전에 정의된 특정 유형으로만 분류되는 경우를 의미한다. 방의 크기를 “대”, “중”, “소”로 나누어 표현하고 있을 때 특정 방의 크기를 “대”라고 명시한다면 이는 범주형 데이터라고 한다.
- factor는 저장할 값 뿐만 아니라 값의 level도 명시해야 한다. 범주형 데이터는 또 다시 명목형과 순서형이 있습니다. 명목형은 값들 크기 비교가 불가능한 경우를 의미하고(좌파,우파) 순서형 데이터는 순서를 둘 수 있는 경우를 의미한다.(대, 중, 소)
- 입력 인자는 일반적으로 vector를 사용합니다.
- levels : 그룹으로 지정할 문자형 vector를 지정한다. 만약 사용하지 않으면 오름차순으로 데이터를 자체적으로 그룹지정 한다.
- ordered : TRUE면 순서형, FALSE면 명목형 데이터를 뜻한다. 기본값은 FALSE이고, level에 지정한 순서대로 값의 크기가 정해진다.
6명의 혈액형 데이터를 vector에 저장하고 vector를 factor로 변환하는 예제이다.

list의 특징
- list는 일반적으로 통계분석의 결과를 저장할 때 많이 사용하는 데이터 형태이다. list의 원소로 scalar, vector, matrix, array, data frame, factor, 또 다른 list를 가질 수 있다.
- list는 vector와 유사한 선형 자료구조이다. list 하나의 메모리 영역에는 key와 value가 한 쌍으로 저장된다. Python의 dict와 유사한 자료구조라고 생각하시면 된다. 단, list는 dict와는 다르게 순서가 존재한다.
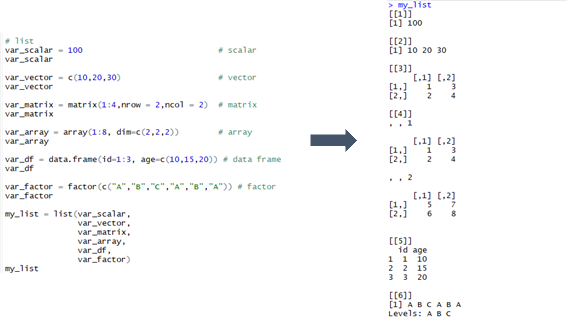
Dataframe의 특징
- 데이터 프레임(Data Frame)은 R에서 가장 많이 사용하는 데이터 형태로 행과 열로 구성된 2차원 형태의 표를 지칭한다.
- 데이터베이스의 테이블 구조와 유사하다.
- column 단위로 서로 다른 데이터의 저장이 가능하다.
- list와 vector의 혼합형으로 column은 list, column내의 데이터는 vector형태이다.
행의 개수가 중요한가? 열의 개수가 중요한가?
- 데이터가 크다는 의미는 행 혹은 열이 많다는 것을 의미하고 데이터 분석 관점에서 본다면 행의 개수보다 열의 개수가 많은 것이 더 중요하다.
- 행의 개수가 늘어나면 같은 로직으로 처리 시간이 늘어나는 것을 의미하지만 열이 늘어나면 변수들의 상관 관계를 분석하는 경우의 수가 늘어나는 것을 의미하기 때문이다.
vector를 이용한 dataframe 생성 예이다.

matrix를 이용한 dataframe 생성 예이다.

3개의 vector를 이용한 dataframe 생성 예이다.
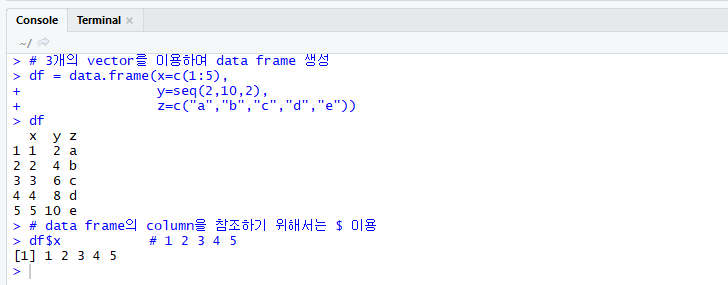
R data frame 데이터 처리 함수
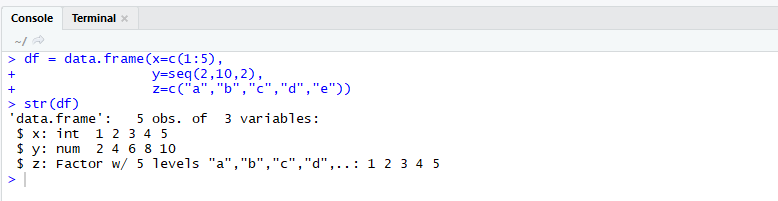
str() 함수는 data frame의 구조를 보여주는 함수이다.
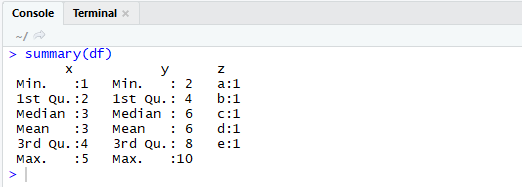
summary()함수는 data frame의 데이터를 대상으로 간단한 통계를 보여주는 함수이다.
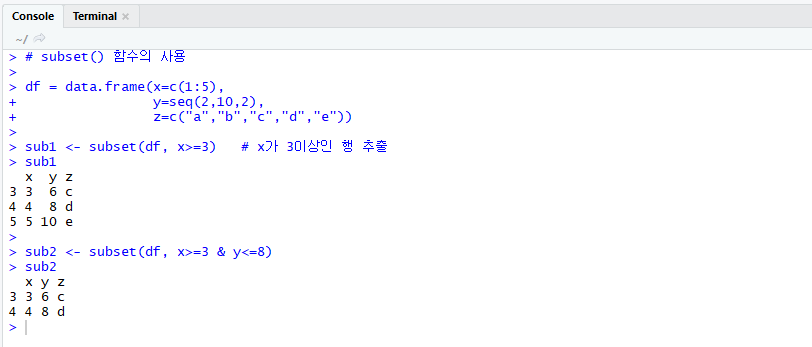
subset()함수는 data frame의 데이터를 대상으로 조건에 만족하는 행을 추출하여 독립된 data frame을 생성하는 함수이다.
728x90
'R' 카테고리의 다른 글
| R 기본 함수 정리 2 (0) | 2021.09.17 |
|---|---|
| R 기본 함수 정리 1 (0) | 2021.09.17 |
| R의 기본형과 자료 구조 1 (0) | 2021.09.16 |
| R소개 및 Rstudio 설치 (0) | 2021.09.15 |





댓글 영역