고정 헤더 영역
상세 컨텐츠
본문
728x90
R에서 알면 좋은 기본적인 함수를 정리해보겠습니다.
순서대로 따라 하면 좋을 것 같습니다.
code : https://github.com/kyeonminsu/R-Study/tree/main/2.기본함수
1. 데이터 조작
데이터 분석업무에서는 데이터 모델링이나 시각화에 적합한 데이터를 얻기 위해 복잡한 과정을 거치게 된다. 분석 프로젝트에서 절반 이상의 시간을 데이터 구축과 변환과 조작, 필터링과 전처리 작업에 할당한다.
- 사용하는 데이터 셋은 ggplot2 package의 mpg data set, hflights package의 hflights data set을 사용한다.
- mpg : 1999년에서 20082008년까지 인기 차종 38개에 대한 연비 데이터..
- hflights : 2011년도 미국 휴스턴에서 출발하는 모든 비행기의 이륙과 착륙 정보가 기록된 것으로 약 2222만 건의 관측치와 21개의 column으로 구성된 데이터 셋
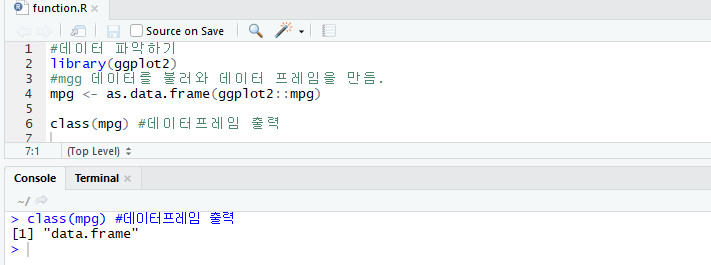
class() : 자료구조(메모리구조)자료구조(메모리 구조)를 파악하기 위한 함수.
ls() : data frame의 column 항목을 vector로 추출하는 함수.

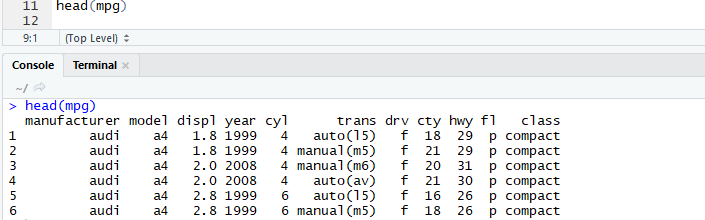
head() : 데이터의 앞부분을 추출하는 함수. 기본값은 5행이지만 data frame일 경우 앞에서 6행까지 추출.
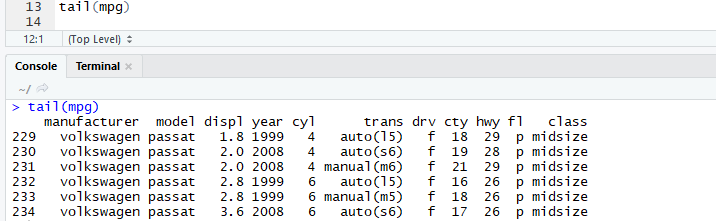
tail() : 데이터의 뒷부분을 추출하는 함수. 기본값은 5행이지만 data frame일 경우 앞에서 6행까지 추출.
View() : View 창에서 데이터 출력.

dim() : data frame의 행과 열의 개수를 구하는 함수. 선형구조에 적용 불가능.

nrow() : data frame의 행의 개수를 구하는 함수. 선형구조에 적용 불가능.

ncol() : data frame의 column의 개수를 구하는 함수. 선형구조에 적용 불가능.

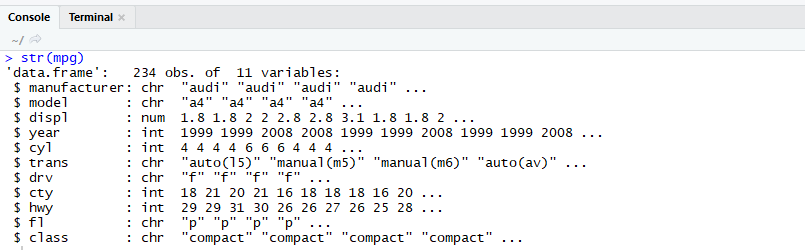
str() : 데이터에 들어있는 column들의 속성을 확인하기 위한 함수.
summary() : 요약 통계량을 산출하는 함수.
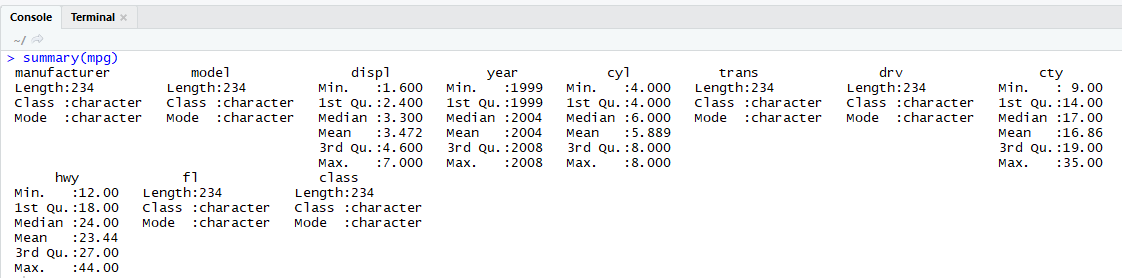
| 출력값 | 통계량 | 설명 |
| Min | 최솟값 | 가장 작은 값 |
| 1st Qu | 1사분위수 | 하위 25% 지점에 위치하는 값 |
| Median | 중앙값 | 중앙에 위치하는 값 |
| Mean | 평균 | 모든 값을 더해 값의 개수로 나눈 값 |
| 3rd Qu | 3분위사수 | 하위 75% 지점에 위치하는 값 |
| Max | 최댓값 | 가장 큰 값 |
length() : 벡터의 길이, data frame일 경우 column의 개수를 구하는 함수.

2. plyr
plyr package는 두 개 이상의 data frame을 대상으로 Key 값을 이용하여 하나의 data frame으로 병합하거나 집단 변수를 기준으로 data frame 변수에 함수를 적용하여 요약 집계 결과를 구할 때 유용한 함수를 제공하는 package이다. install.packages("plyr")로 패키지 설치를 한다.
x와 y의 각각 데이터 프레임을 만들어 준다.

join() : key 값을 기준으로 두 개의 data frame을 하나로 병합을 한다. join에도 4가지 방식이 있다.
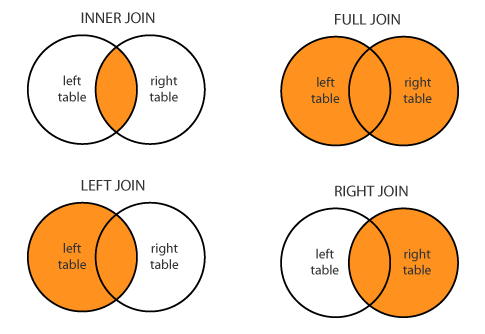
inner join : key를 기준으로 두 테이블에 같이 존재하는 데이터를 추출한다. 교집합의 개념과 동일하다.
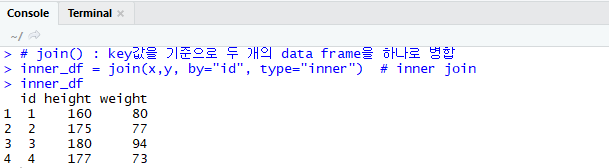
left join : 왼쪽에 있는 테이블의 key을 기준으로 병합한다.
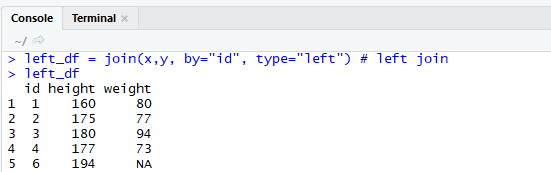
right join : left join과 반대로 오른쪽 테이블의 key을 기준으로 병합한다.

full join : 키(key)를 기준으로 두 테이블에 존재하는 모든 데이터를 뽑아내어 병합한다.

tapply() : 집단별 통계치를 구해주며 한 번에1개의 통계치만 구할 수 있다.
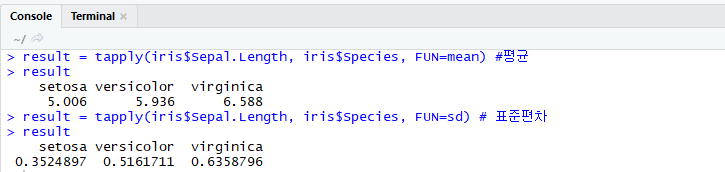
ddply() : 한번에 여러 개의 통계치를 구할 수 있다.

728x90
'R' 카테고리의 다른 글
| R 기본 함수 정리 2 (0) | 2021.09.17 |
|---|---|
| R의 기본형과 자료 구조 2 (0) | 2021.09.16 |
| R의 기본형과 자료 구조 1 (0) | 2021.09.16 |
| R소개 및 Rstudio 설치 (0) | 2021.09.15 |





댓글 영역